What if we tell you that there is a whole different section of trading where only the elites of the trading realm reside? It is not that a newbie cannot enter it; they will mostly lose their money on that platform.
The name of these trading assets is Over The Counter or OTC. It is not that popular among new traders, but it surely gets some popularity among the advanced-level traders. Most traders switch to OTC when they are not getting the desired prices for their assets through the listings.
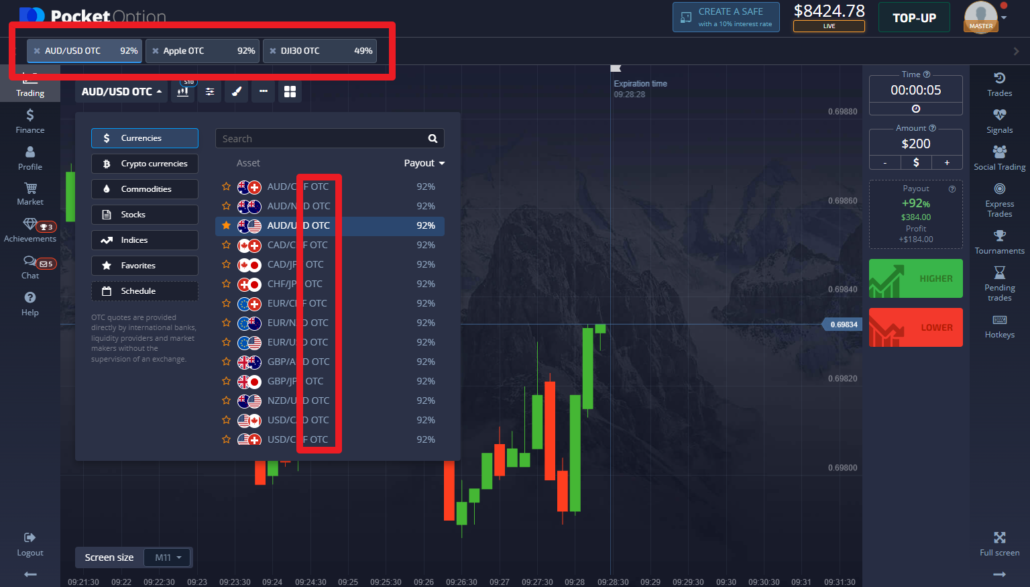
Thus many traders are seen to move to OTC to get their desired deals.
Maybe you ask yourself ‘How to trade OTC binary options‘, ‘What is an OTC market binary options‘, or ‘What does OTC mean in binary options‘. We have the answers for you. This article will discuss the basic definition and the risk involved in dealing with OTC. This will allow you to make a conscious decision about whether you want to trade here or not.
To start experimenting and learning the basics of trading, you can sign-up on Quotex and start trading without losing any money.
Over-the-counter market definition:
An over-the-counter market or OTC is where the trading happens directly between the two parties without involving any third-party broker. The trading directly happens in stocks, commodities, currencies, or instruments; the methodology and process for trading are quite different from the traditional auction market system.
The dealers of the over-the-counter market quote the prices for selling or buying the asset. The quoted prices remain between the two parties; any other investors or buyers of the market are not aware of the dealing prices in OTC. Therefore, the dealings are subjected to a fewer number of regulations, as compared to the auction market.
OTC is the premium platform in the realm of trading. The dealers in these platforms do not have physical locations or makers. The assets traded in the over-the-counter market are derivatives, currencies, bonds, and structured products. The most interesting point of an over-the-counter market is, traders can also trade equities at the quoted prices.
In the USA, this market is controlled by FINRA.
What is OTC In Binary Options Trading? Should you trade it?
In the paragraph mentioned above, we discussed what OTC is in binary options trading? Should you trade, it is the biggest question of all time. Thus, in the upcoming paragraphs, we will discuss if one should or should not trade in OTC and the options available to trade-in.
What are OTC Options?
Before discussing whether you should or should not trade over the counter. You need to be well versed in what binary options OTC are to make an effective trading decision. OTC options are defined as exotic options traded at OTC rather than a normal exchange-traded option contract.
The OTC options are extremely private between the buyer and the seller. There is no standard price for the assets; the two individual parties are quoting the prices. They are supposed to define their terms and conditions along with the expiration dates. In the OTC market, there is no secondary market involved while trading.
Understanding the trading mechanism at OTC
The mechanism and process used while trading at the over-the-counter market, thus understanding the trading mechanism at OTC, is extremely important. Investors usually make a switch to OTC when the listed options are not meeting their trading needs.
Mostly only the two parties are involved in OTC, but a Government based third party can also be involved to regulate the deal; for example, FINRA regulates the OTC market in the USA. Considering the restrictions on the listed deals, the hedgers and the speculators tend to reduce those terms and conditions to achieve their desired deal.
The OTC options differ in platforms and assets since it is more of a private transaction between the buyer and a seller. During the exchanges, the options must clear out through the clearinghouse. Thus, the clearinghouse seems to play the role of the middle man in the process of trading.
There are specific terms set considering the strike price and the expiration date of the deal. Since it is more of a private affair, the buyers and sellers can use a combination of the strike price and the expiration date, depending upon the interest of both parties. Some terms and conditions might be quite different from the usual ones of the trading realm.
Since there is no disclosure of the deal from both parties, there is a high possibility that the parts of the contract are not honored by either of the parties. In this case, taking legal action might also get difficult. As a result, the traders might not enjoy the same level of protection as they did in the normal auction market.
Since there are no third-party platforms involved in OTC trading, the only option to close an OTC deal is to create an offset transaction. As a result, the effects of the original trade are usually seen to get nullified due to the offset transaction. This point is a huge contrast to the trading norms of the normal auction market.
Risks of over-the-counter trading
The over-the-counter market is a completely different sector of trading. Thus the risks of over-the-counter trading are also quite different from those of normal online trading. Here are some of the major risks involved in over-the-counter trading:
- First, it is challenging to find any form of reliable information or data about the company. Thus it increases the risk of getting scammed during the deal.
- Second, most of the stocks or shares are exchanged on thinly traded markets. Thus the probability of gaining a good profit is further lowered.
- Third, it is complicated for investors to invest in the company’s assets without any reliable information. Thus the company usually does not buy the stocks in bulk, as in the normal auction market.
- Since the disclosure terms and conditions are different for OTC, getting cheated is also quite high.
- Fourth, the company’s evaluation is impossible since public information is not available for the OTC companies.
Here is the link to a video guide about trading in the over-the-counter market.

By loading the video, you agree to YouTube’s privacy policy.
Learn more
Advantages and disadvantages of OTC
The over-the-counter market is quite a contrast to the average trading system; thus, before investing, you need to be well versed with the basic pointers of the system. Thus here are the advantages and disadvantages of OTC.
Advantages of OTC:
- It is a really good option for the traders who are just active on the weekends; they will not miss good deals, unlike the average trading system.
- Quotex provides you with various assets to trade on, and it is one of the best options for trading on OTC.
- You can also start trading with a minimum of $1, unlike the average trading system.
Disadvantages of OTC:
- It is impossible to track if the prices of the assets will rise or fall. You cannot even cross-check if the rise or fall in the prices is real; it can also be a big scam.
- The strategies seen working in the official market are hardly seen to work in the over-the-counter market.
- Only a small group of investors can manage the rise or fall of the prices. Thus technical indicators are of no use here.
- This market is not for a newbie.
- Sometimes either of the parties may lose upon various fundamentals due to a lack of knowledge of the asset.
Top 7 best strategies for OTC Binary Options trading:
You should note that even though the strategies we are about to discuss are tried and tested, they do not continually result in high profits. A volatile market does not guarantee profits even with the right binary options strategy. Sometimes, you may even discover yourself in losses.
Binary options provide serious profits, but the risks are hefty enough to make traders question their investment limit. Hence, we advise you to keep your investments minimum in binary options.
1. Follow trends
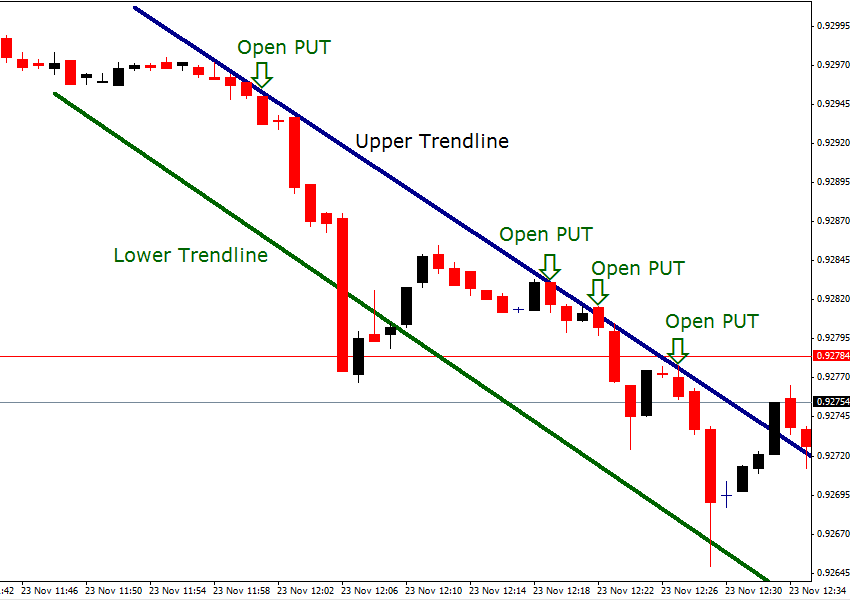
No matter in what market you are trading or in what stock you invest in, following the market trends is a must to gain profits. Asset costs change with the trends, and the prices of the related assets will react accordingly.
The binary options market is established on the trader’s assumptions. If they think that the price of a particular asset will go up, they will invest in that asset and vice versa. Due to this, trends mostly follow a zigzag pattern.
To use this technique, study the charts carefully and look where the trend lines are going. If the line is flat, look for another asset to trade. If you see a line is advancing, there’s a good possibility that the prices will increase.
2. Follow the news
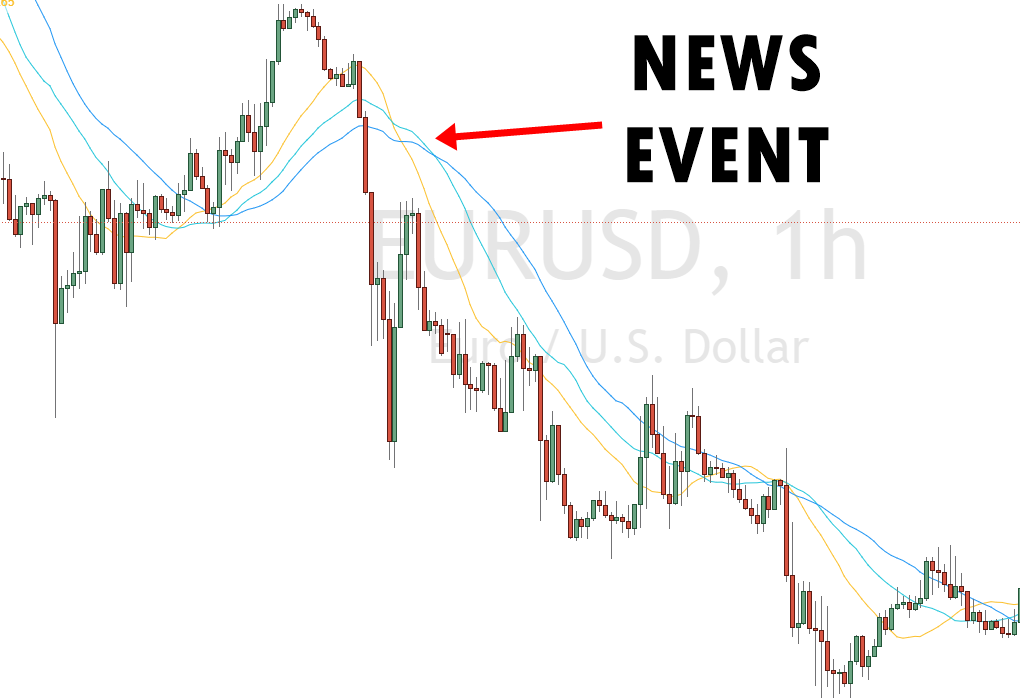
As a trader, you should know what is happening in the market. It will help predict how the asset’s price will fluctuate. You may find that following the news events is much easier than technical analysis of the trends, charts, etc.
You can subscribe to various newsletters, radio stations, and newspapers that give financial news. Once you choose an asset, follow the related tech companies and determine when an announcement will be made. If they will release a new product soon, opt for the purchase options and wait for the earnings to come once the product gets released.
3. The straddle strategy

The straddle strategy closely works with the news strategy. For this OTC binary options strategy to work, a trader will make straddle trades before that important announcement mentioned in the previous section.
Asset value can increase for a short period after the announcement is made by the company. In this case, you will purchase an option that estimates that the price will get lower once again.
Once it starts to drop, purchase another option, but this time predict that the prices will increase again. Hence, you use the trend swings to make money regardless of the price fluctuations of the option chosen.
(Risk warning: Your capital can be at risk)
4. The Pinocchio strategy
The Pinocchio strategy involves the trader trading against the ongoing trend. If an asset follows a price-rising trend, the Pinocchio technique would suggest placing an option that expects the price of that asset to fall. You will expect the opposite if the asset follows a price-declining trend.
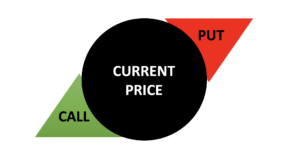
Examine the candlestick chart and identify if the market is bearish or bullish at the time of the trade. Suppose it is a bear market; set your call option. If it is a bullish market, place a put option.
5. The candlestick formation patterns strategy
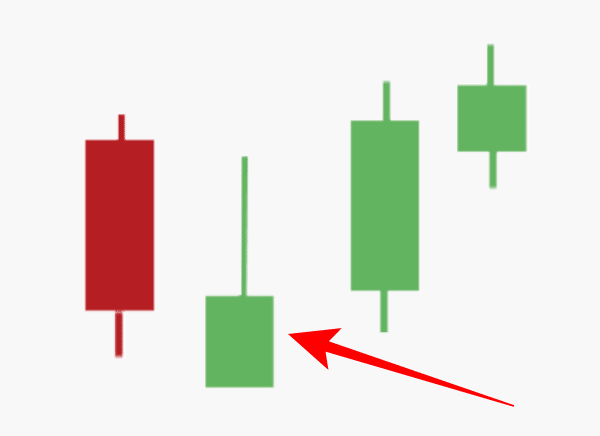
This OTC trading strategy requires you to read the asset chart and ascertain how its price will change over time. The candle’s bottom indicates the lowest price the asset has reached, and the highest historical price is known as the top of the candle. You can also see the opening and closing prices of the trade.
You will see a pattern in the price fluctuations of the asset while investigating its history. It will indicate that the price rises or falls during certain times. Hence, the traders rely on this information to place or put options on the trade.
(Risk warning: Your capital can be at risk)
6. Fundamental analysis
This Binary OTC strategy helps traders learn about an investment with more precision. It is very famous among the day traders. The primary goal is to collect data about the asset you are trading. It will help the traders generate profits from that asset with future bids.
For instance, you are unfamiliar with how a particular asset works. If the market is volatile and has the potential to generate profits, start by placing a small bid on that asset. That will assist you in finding whether a strategy is profitable or not.
If you earn the profits from that small trade, you can invest a high amount for higher gains. But if you suffer from losses, consider changing your strategy.
7. The hedging strategy
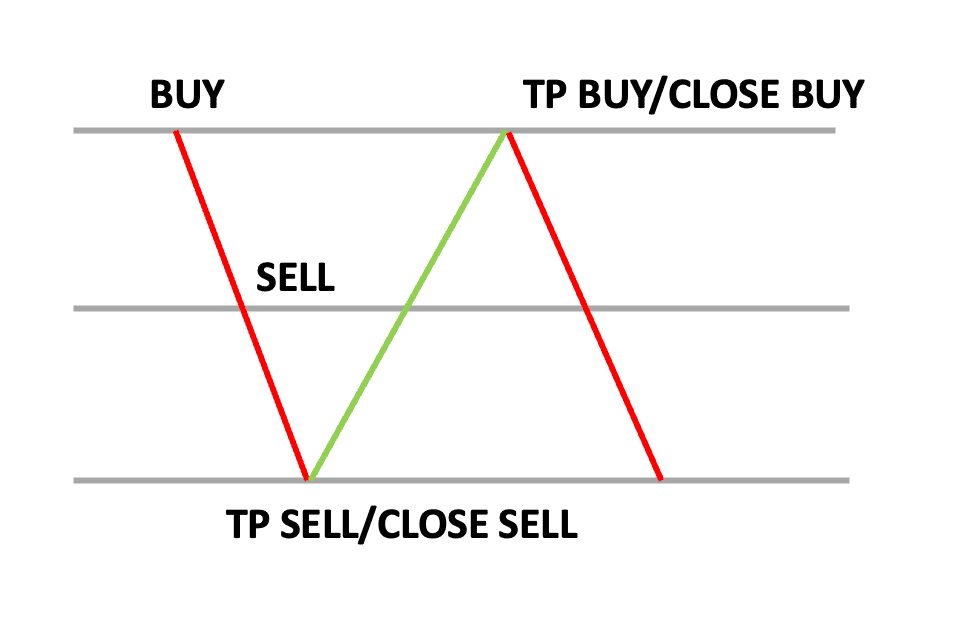
For beginners, the hedging strategy is worth trying. It is simple to execute, but the profit generation is not always accurate. The trader will place both a call and a put option on an asset simultaneously.
This strategy ensures that you will make money, despite where the price move. Even though the risk involved is less, you will have to measure the risk and cost of losing th
Conclusion: Is OTC trading recommendable?
In this article, we discussed the over-the-counter market (OTC) quite in-depth. As a result, you might have understood the positives and negatives of trading at OTC. Thus you can make a conscious decision about trading on OTC.
Trading over the counter is not recommended for newbies. The minimum cost of trading might sound very attractive to new traders, but they can lose a lot of money since they are not familiar with the basic OTC binary strategies or knowledge of trading.
If you are new to trading, always start with the auction market. Practice and experiment there to develop your trading strategies. You can also sign-up with Quotex to learn trading from scratch. You can [practice and experiment there without losing any money while trading.
(Risk warning: Your capital can be at risk)
Frequently asked questions:
Is it hard to buy or sell Binary Options at OTC?
Yes, sometimes it can be tough to buy or sell Binary Options at OTC. The pace of trading on OTC is comparatively slow, as the number of buyers and sellers is limited.
Does OTC Trading affect the price of the asset?
Yes, OTC trading surely affects the prices of the asset. The asset’s value is usually seen to increase at OTC, as the demand is relatively high on this platform.
Which OTC strategies for Binary Options can be used?
Basically, the same strategies can be used for OTC trading as for normal binary charts. The same rules apply. An OTC Binary Options chart will have the same movements and character as normal charts. So it is recommended not to change the trading strategies.