Fibonacci Retracement stratejisi, Fibonacci dizisinin yüzdelerine dayalı olarak potansiyel destek ve direnç seviyelerini tahmin etmek için kullanıldığından yatırımcılar için mükemmeldir. Bu yazıda kullanımı ve etkinliği hakkında daha fazla bilgi ele alacağız.

Bunu bildiğim iyi oldu:
- Fibonacci Retraksiyonu, Fibonacci dizisinin yüzdelerine dayalı olarak potansiyel destek ve direnç seviyelerini tahmin etmek için kullanılır.
- Araç, piyasaların değişken doğası ve çizgilerinin subjektif yerleşimi nedeniyle kusursuz değildir ve bu da yatırımcıların farklı yorum yapmasına yol açabilir.
- En iyi şekilde trendin güçlü olduğu piyasalarda kullanılır ve yatırımcıların, alım satımların giriş ve çıkış noktaları hakkında spekülasyon yapmak için grafikler üzerinde yüzde çizgileri çizmelerini gerektirir.
- Faydalı olsa da yatırımcılar Fibonacci düzeltmesine tek başına güvenmemeli ve onu diğer araçlarla birlikte ve daha geniş bir ticaret stratejisi dahilinde kullanırken sınırlamalarını dikkate almalıdır.
Bu Yazıda Okuyacaklarınız
Fibonacci Düzeltme aracı nedir?
Fibonacci Retracement, genellikle ikili opsiyon piyasasının doğasını anlamak için kullanılan güçlü bir teknik analiz aracıdır. Bu teknik gösterge aynı derecede işlevseldir MACD olarak ve hareketli ortalama göstergesi.
Fibonacci Retracement aracını özel yapan şeylerden biri de tarihidir. Bu araç, binlerce yıllık matematiksel gözlemlere dayanmaktadır. Bu aracın yardımıyla tüccarlar, destek alanlarını ve direnç için potansiyel hedefleri tahmin edebilir.
Son zamanlarda, Fibonacci Düzeltme, basit ve kolay bir yöntem geliştirmeye yardımcı olduğu için tüccarlar arasında popüler bir araç haline geldi. ikili opsiyon ticaret stratejisi. Bu göstergeyi kullanarak, herhangi bir tüccar, bir fiyat-zaman çizelgesi aracılığıyla bir varlık veya ikili opsiyon fiyatını takip edebilir.
Teknik Göstergelerin Rolü ve Fibonacci Gerilemesinin Gücü
Basit evet veya hayır önermesine bağlı olduğu için ikili opsiyon ticareti hızlı bir şekilde gerçekleştirilebilir. Tüccarlar, piyasayı anlayarak, finansal haberlerden haberdar olarak ve fiyat trendlerini tespit ederek teklifi belirleyebilirler.
Ancak, doğası gereği değişken olduğu için ikili opsiyonların piyasa hareketi nasıl tahmin edilebilir? Cevap teknik göstergelerdir. Ticaret göstergeleri, piyasa modellerini anlamak için grafikler ve çizelgelerde kullanılan matematiksel değer olarak görülebilir.
Teknik göstergeler, tüccarın piyasa hakkında daha iyi bir fikir edinmesine yardımcı olur, böylece büyük bir karlılıkla ticarete girip çıkabilirler. Göstergeler momentum, volatilite, trend ve hacim olmak üzere dört kategoriye ayrılmıştır.
Mevcut birçok seçenek olduğundan, kendiniz için bir teknik göstergeyi kolayca bulabilirsiniz. Bununla birlikte, gelecekteki fiyat dönüşünü tahmin etmenize yardımcı olabilecek bir gösterge kullanmak istiyorsanız, seçiminiz Fibonacci Geri Çekilme olmalıdır.
Bu gösterge herkes için değildir. Bununla birlikte, doğru kullanılırsa, bir varlığın gelecekteki fiyat hareketi doğru bir şekilde tahmin edilebilir.
Ama bu ticaret aracı kusursuz mu? Dezavantajları nelerdir? Ve ikili opsiyon ticaretine nasıl yardımcı olabilir? Pekala, bu soruların cevaplarını ve daha fazlasını bulmak için bu yazıyı okumaya devam edebilirsiniz.
Farklı Fibonacci Geri Çekilme seviyeleri nelerdir?

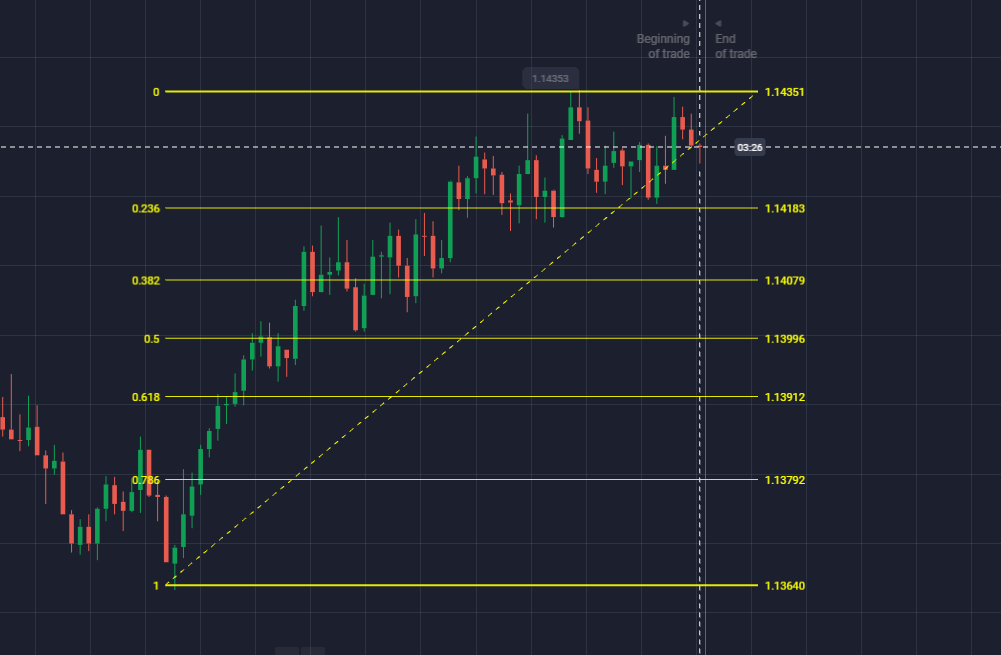
Fibonacci Geri çekilme seviyeleri grafikte yatay çizgilerle temsil edilir. Bu çizgiler grafikteki destek ve direnç seviyesini temsil eder. Seviyeler Fibonacci dizisinden türetilir ve yüzde olarak temsil edilir.
Burada yüzde, fiyatın önceki bir hareketin ne kadarını geri çektiğini gösterir. Altı seviye 23.6%, 38.2%, 50%, 61.8%, 78.6% ve 100%'dir. Bunun yanında 50% de bir Fibonacci oranıdır. Ancak resmi olarak onaylanmamıştır. Bu yüzdeler, bir tüccarın grafikte bir varlığın fiyatının tersine döneceği veya duracağı alanlar hakkında bilgi sahibi olmasına yardımcı olur.
Yatırımcılar, bir varlığın düşük ve yüksek olmak üzere iki önemli fiyat noktası arasında seçim yapmak için Fibonacci Retracement göstergesini kullanabilir. Bundan sonra gösterge iki fiyat noktası arasında bir seviye oluşturur.
Örneğin, bir varlığın fiyatı $10 artar ve ardından $2.36 düşer. Bununla, fiyatın 23.6% tarafından geri çekildiği sonucuna varabilirsiniz. Fibonacci Retracement ayrıca stoploss seviyesini belirlemek, giriş emirleri vermek ve fiyat hedeflerini belirlemek için kullanılır.
Fibonacci Retracement seviyeleri nasıl hesaplanır?
Fibonacci Retracement seviyesini hesaplamak için verilmiş bir formül yok. Ancak iki uç noktayı seçerek konumu hesaplayabilirsiniz. Daha sonra bu iki noktayı birleştiren bir çizgi çizmeniz gerekiyor.
Birleştirme çizgisi, iki nokta arasındaki fiyat eğilimini gösterdiği için eğilim çizgisi olarak adlandırılır. Yüzde hareket ettiğinde diğer çizgiler çizilebilir.
Örneğin, bir öğenin fiyatı $10'dan $15'e değişir. Bu iki noktayı bir geri çekilme göstergesi çizmek için kullanabilirsiniz. Şimdi, öğenin 23.6%'sini hesaplamak için hızlı bir hesaplama yapmanız gerekiyor.
$15 – ($5 x 0,236) = $13,82
Bu hesaplamadan sonra bir tüccar olarak eşyanın 23.6% seviyesinin $13.82 fiyat seviyesinde olacağı sonucuna varabilirsiniz.
Fibonacci Retracement, İkili Opsiyon ticaretine nasıl yardımcı olabilir?

Fibonacci Retracement'ı kullanmak için, tüccarlar grafikte yüzde çizgileri çizmelidir. Bu çizgiler, fiyat değişikliklerinin piyasada nerede olacağını tahmin etmeye yardımcı olur. Bu veriler, ikili opsiyonları ne zaman satın almanız veya satmanız gerektiğini tahmin etmenize yardımcı olabilir.
Fibonacci Retracement aracını kullanırken tüccarların hatırlaması gereken üç kural vardır.
- Fibonacci Retracement seviyesi bir sinyal olarak görülmemelidir. Bunun nedeni, ikili opsiyon ticaret piyasasında sinyalin ortaya çıkma ihtimalinin yüksek olduğu seviye olmasıdır.
- Geri izleme yüzdelerinden birinde meydana gelen sinyaller, diğer seviyelerdekilerden daha iyidir. Ancak bazen iki hat arasında güçlü bir sinyal de oluşur.
- İşlem grafiğindeki geri çekilme seviyesi bir kez bile kırılırsa, hedef bir sonraki düzeltme seviyesine kayar. Hareket önceki seviyeden daha güçlüyse, hareket aynı yönde devam eder.
(Risk uyarısı: Sermayeniz risk altında olabilir)
Fibonacci Retracement seviyeleri nasıl kullanılır?
Fibonacci Retracement aracından daha fazla karlılık elde etmek için birkaç şeyi hatırlayabilirsiniz.
- Altın, EURUSD ve daha fazlası gibi güçlü trend olan finansal enstrümanlarla ticaret yapmalısınız.
- Günlük bir çizelge gibi doğru bir zaman çerçevesi kullanın.
Ma'nın doğasını anlamak için önceki fiyat hareketlerini de analiz edebilirsiniz. Örneğin, geri çekilme seviyesini hesaplamak için bir öğenin fiyat artışını aşağıdan yukarıya doğru hesaplarsanız. Ölçülen seviye, yükseldikten sonra yukarı doğru hareket etmeye devam ettiğinde fiyatın geri çekilmesini anlamanıza yardımcı olabilir.
Benzer şekilde, geri çekilme seviyesini bilmek için fiyat düşüşünü yukarıdan aşağıya hesaplayabilirsiniz. Bu seviye, düştükten sonra aşağı yönde hareket etmeye devam eden bir varlığın fiyatının geri çekildiğini gösterir.
Yükseliş yönündeki tüccarlar satın alma kalıplarını kullanır. Aynı şekilde, düşüş trendi yönündeki tüccarlar da satış modelini kullanır.

Fibonacci Düzeltme aracı kusursuz mu?
Fibonacci Retraksiyonu bir varlığın fiyat hareketini bilmenin mükemmel bir yolu olsa da kusursuz değildir. Çünkü belli sınırlamaları var.
Yeni bir yatırımcı ikili opsiyon piyasasını anlamak için Fibonacci Retracement aracını kullanıyorsa, muhtemelen grafikte gösterilen verileri ve çizgileri kullanacaktır. Ancak deneyimli bir tüccar, doğru bilgiyi bulmak için her zaman çizgileri ayarlar.
Ek olarak, ikili opsiyon piyasası değişkendir. Dolayısıyla, bir varlığın tam durumunu veya fiyat hareketini tahmin etmek neredeyse imkansız hale geliyor. Ve tüccarlar bu tür verileri kullandıklarında, ticarete yatırdıkları parayı kaybetmeleri muhtemeldir.
Ayrıca, Fibonacci Geri Çekilme seviyesi, piyasadaki fiyatın tam dönüm noktasını belirlemez. Tahmini bilgi alabilirsiniz, ancak bunu tam fiyat noktalarıyla karıştıramazsınız.
Bahsetmemek gerekirse, Fibonacci Geri Çekilme kavramının tamamı sayılara ve hesaplamalara dayanmaktadır. Hesaplama Fibonacci yüzdesine göre yapılırken, hiçbir mantık yoktur.
Mantık eksikliği nedeniyle, Fibonacci Düzeltme, mantık arayan tüccarlar için karmaşık bir gösterge haline gelir. onların ticaret stratejisi.
Broker Araçları
Şüphesiz, Fibonacci Düzeltme, bir varlığın fiyatını belirlemenin mükemmel bir yoludur. Ancak, hesaplamalar, sayılar ve oranlar bir tüccarı bunaltabilir.
Ancak, tüm hesaplamaların kolay ve hızlı çalışmasını sağlamak için gelişmiş grafik yazılımıyla birlikte gelen güçlü bir aracı aracı kullanabilirsiniz.
İşte Fibonacci grafik desenleri sunan bazı popüler brokerler.
Quotex
Daha düşük minimum depozito miktarına sahip bir ticaret platformu arıyorsanız, seçiminiz Quotex olmalıdır. Minimum $5 depozito gerektirir. Parayı yatırdıktan sonra bir demo hesabına erişebilirsiniz.
Quotex ile işlem yaparken, herhangi bir opsiyon işlem platformu tarafından sunulan en yüksek ödeme oranı olan 98%'lik bir ödeme oranı bekleyebilirsiniz. Ancak, bu komisyoncu yasal olarak kayıtlı değil.
(Risk uyarısı: Sermayeniz risk altında olabilir)
IQ Option
IQ Option, CySEC'in düzenlediği iyi bilinen bir ikili opsiyon ticaret platformudur. Bu güvenilir komisyoncunun minimum $10 depozitoya ihtiyacı var. Para yatırdıktan sonra, Fibonacci grafik desenlerini kullanarak IQ Option ile işlem yapmaya başlayabilirsiniz.
Minimum tutarı yatırdıktan sonra demo hesabına da erişebilirsiniz. Ve IQ Option tarafından sunulan ödeme oranı 90%'dir.
(Risk uyarısı: Sermayeniz risk altında olabilir)
RaceOption
RaceOption, Fibonacci grafik kalıplarını kullanarak paranızı ikili opsiyon piyasasına yatırmak için kullanabileceğiniz başka bir ticaret platformudur. Platform 2014 yılında piyasaya sürüldü ve 90% ödeme oranı sunuyor.
RaceOption'den işlem yapmak için gereken minimum depozito $250'dir. Tutar biraz yüksek olsa da buna değer çünkü bu komisyoncu ödediğiniz miktara göre üç farklı ticaret platformuna erişim sunuyor.
(Risk uyarısı: Sermayeniz risk altında olabilir)
Sonuç – Fibonacci Retracement, ticaret hedeflerinize ulaşmanıza yardımcı olabilecek mükemmel bir araçtır
Fibonacci Retracement, birden fazla yatırımcının ikili opsiyon piyasasını analiz etmek için kullandığı popüler bir alım satım aracıdır. Fibonacci çizgilerini kullanarak, tüccarlar bir varlığın fiyat eğilimi hakkında bir fikir edinebilirler.
Ancak, bu verilere tamamen bağlı kalınmamalıdır, çünkü bir varlığın piyasadaki fiyatının tam dönüm noktasını söylemez. Ayrıca, bu göstergenin tüccarların göz ardı edemeyeceği bazı sınırlamaları vardır.
Ama sonuçta, Fibonacci Retracement, ticaret hedeflerinize ulaşmanıza yardımcı olabilecek mükemmel bir araçtır.
Fibonacci Retracement aracı hakkında sık sorulan sorular:
İkili Opsiyon Ticaretinde Fibonacci Geri Çekme Aracı Nedir?
Fibonacci Retracement aracı, ikili opsiyon ticaretinde potansiyel destek ve direnç seviyelerini tahmin etmek için kullanılan bir teknik analiz aracıdır. Fibonacci dizisine dayanır ve yatırımcıların bir grafik üzerinde belirli yüzde seviyelerinde (23.6%, 38.2%, 50%, 61.8%, 78.6% ve 100%) yatay çizgiler çizerek piyasadaki olası dönüş noktalarını belirlemelerine yardımcı olur.
Fibonacci Geri Çekilme Düzeylerini Nasıl Hesaplarsınız?
Fibonacci Gerileme seviyelerini hesaplamak için varlığın grafiğinde iki önemli fiyat noktası (genellikle yüksek ve düşük nokta) seçin. Bu noktaları birleştiren bir çizgi çizin ve ardından Fibonacci yüzdelerini bu çizgiye uygulayın. Örneğin, bir varlığın $10'dan $15'e taşınması durumunda 23,6% geri çekilme seviyesi $15 – ($5 x 0,236) = $13,82 olarak hesaplanır.
Fibonacci Geri Çekme Aracı Piyasa Hareketlerini Tahmin Etmede Kusursuz mudur?
Hayır, Fibonacci Retracement aracı kusursuz değildir. Potansiyel destek ve direnç seviyelerini tahmin etmek için değerli bir araç olsa da piyasa oynaklığı ve çizgilerini yerleştirmenin subjektif doğası nedeniyle sınırlamaları vardır. Yatırımcılar bunu daha geniş bir stratejinin parçası olarak kullanmalı ve ticari kararlar alırken yalnızca ona güvenmemelidir.
İkili Opsiyon Ticaretinde Fibonacci Gerilemesini Kullanmanın En İyi Uygulamaları Nelerdir?
Fibonacci Retracement'ı kullanırken, güçlü trende sahip finansal araçlarla işlem yapmak ve günlük grafik gibi doğru bir zaman dilimi kullanmak en iyisidir. Piyasanın doğasını anlamak için önceki fiyat hareketlerini analiz edin ve geri çekilme seviyelerinin sinyal değil, sinyallerin oluşabileceği noktalar olduğunu unutmayın. Bu aracın diğer göstergeler ve analiz yöntemleriyle birlikte kullanılması da önerilir.





